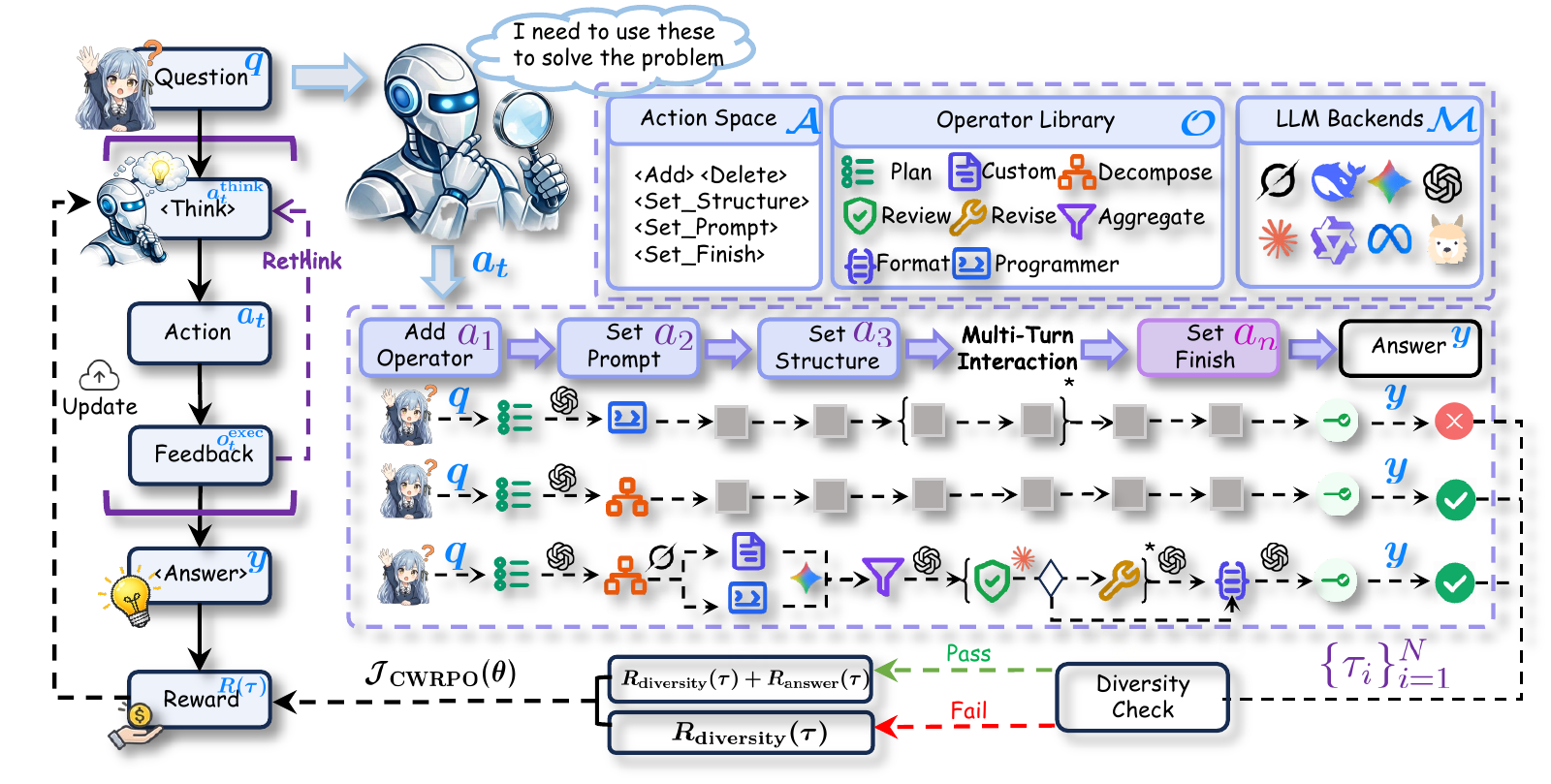
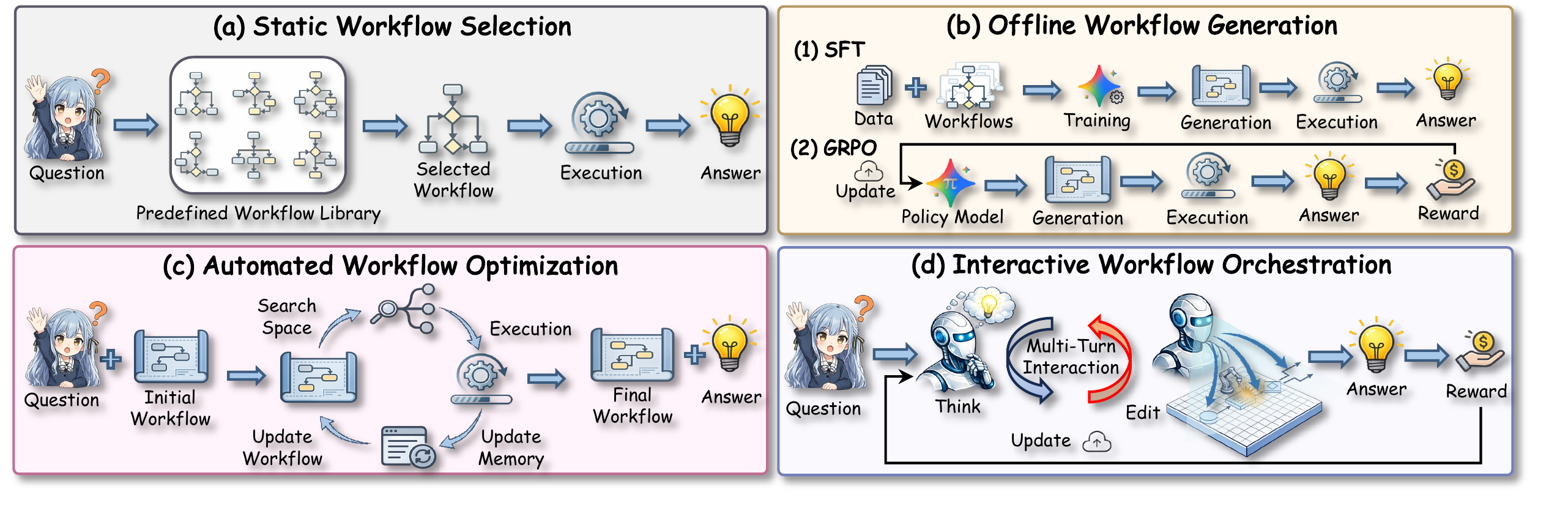
In recent years, a variety of powerful agentic workflows have been applied to solve a wide range of human problems. However, existing workflow orchestration still faces key challenges, including high manual cost, reliance on specific operators/large language models (LLMs), and sparse reward signals. To address these challenges, we propose FlowSteer, an end-to-end reinforcement learning framework that takes a lightweight policy model as the agent and an executable canvas as environment, automating workflow orchestration through multi-turn interaction. In this process, the policy model analyzes execution states and selects editing actions, while the canvas executes operators and returns feedback for iterative refinement. Moreover, FlowSteer provides a plug-and-play framework that supports diverse operator libraries and interchangeable LLM backends. To effectively train this interaction paradigm, we propose Canvas Workflow Relative Policy Optimization (CWRPO), which introduces diversity-constrained rewards with conditional release to stabilize learning and suppress shortcut behaviors. Experimental results on twelve datasets show that FlowSteer significantly outperforms baselines across various tasks.
Multi-turn interaction between a lightweight policy model (Flow-Director) and an executable canvas environment for iterative workflow construction and refinement.
Supports 12 diverse operators across 6 categories and interchangeable LLM backends without task-specific fine-tuning of the execution model.
Canvas Workflow Relative Policy Optimization with diversity-constrained rewards and conditional release mechanism for stable learning.
Significantly outperforms baselines across 12 datasets spanning QA, mathematical reasoning, and code generation tasks.
Lightweight policy model (Qwen3-8B) that analyzes workflow states and selects editing actions through multi-turn interaction.
Executable environment that maintains workflow graph state, executes operators, and provides real-time feedback.
End-to-end RL with diversity-constrained rewards to optimize both workflow structure and task correctness.
| Dataset | Metric | Baseline | SFT | GRPO | AFlow | Agent+RL (4o-mini) | Ours | |||
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3-8B | 4o-mini | Qwen3-8B | Qwen3-8B | 4o-mini | Agentflow | Router-R1 | Orchestrator | FlowSteer | ||
| In-Distribution (IID) Benchmarks | ||||||||||
| GSM8K | Acc. | 91.41 | 92.97 | 92.19 | 92.97 | 94.53 | 93.75 | 94.01 | 93.94 | 96.09 (+3.12) |
| MATH | Acc. | 66.41 | 60.94 | 61.72 | 68.75 | 70.31 | 71.87 | 76.56 | 72.26 | 81.25 (+20.31) |
| HotPotQA | EM | 67.19 | 63.28 | 70.31 | 59.38 | 68.75 | 67.19 | 72.00 | 67.97 | 78.12 (+14.84) |
| F1 | 74.05 | 73.03 | 75.25 | 64.95 | 77.90 | 77.88 | 79.84 | 75.61 | 84.98 (+11.95) | |
| SQuAD v2 | EM | 54.69 | 47.66 | 73.44 | 66.41 | 73.44 | 64.06 | 59.84 | 70.34 | 78.12 (+30.46) |
| F1 | 61.54 | 59.42 | 77.31 | 72.00 | 82.41 | 72.45 | 65.29 | 75.24 | 83.67 (+24.25) | |
| MBPP | Pass@1 | 63.28 | 64.84 | 57.03 | 77.34 | 83.20 | 79.69 | 73.43 | 74.22 | 84.38 (+19.54) |
| HumanEval | Pass@1 | 81.25 | 82.81 | 61.72 | 86.72 | 90.62 | 87.50 | 85.15 | 89.06 | 92.96 (+10.15) |
| Out-of-Distribution (OOD) Benchmarks | ||||||||||
| MathQA | Acc. | 75.00 | 79.69 | 61.71 | 60.15 | 83.59 | 82.81 | 80.47 | 82.03 | 88.67 (+8.98) |
| AIME 2025 | Acc. | 16.66 | 10.00 | 0.00 | 8.33 | 13.33 | 10.00 | 10.00 | 20.00 | 26.67 (+16.67) |
| TriviaQA | EM | 60.16 | 71.09 | 60.94 | 59.38 | 73.44 | 75.00 | 75.78 | 77.36 | 79.69 (+8.60) |
| F1 | 69.17 | 81.40 | 69.88 | 69.23 | 82.50 | 81.47 | 80.43 | 83.23 | 84.11 (+2.71) | |
| NaturalQuestions | EM | 39.84 | 39.84 | 46.09 | 43.75 | 42.97 | 45.70 | 49.22 | 50.00 | 54.69 (+14.85) |
| F1 | 50.75 | 51.42 | 53.40 | 53.24 | 49.92 | 55.98 | 52.79 | 55.41 | 62.56 (+11.14) | |
| APPS | Pass@1 | 39.84 | 40.62 | 26.56 | 34.38 | 42.97 | 41.41 | 42.95 | 44.53 | 49.21 (+8.59) |
| DS-1000 | Pass@1 | 34.38 | 45.31 | 25.78 | 38.28 | 53.91 | 46.88 | 42.97 | 51.56 | 58.59 (+13.28) |
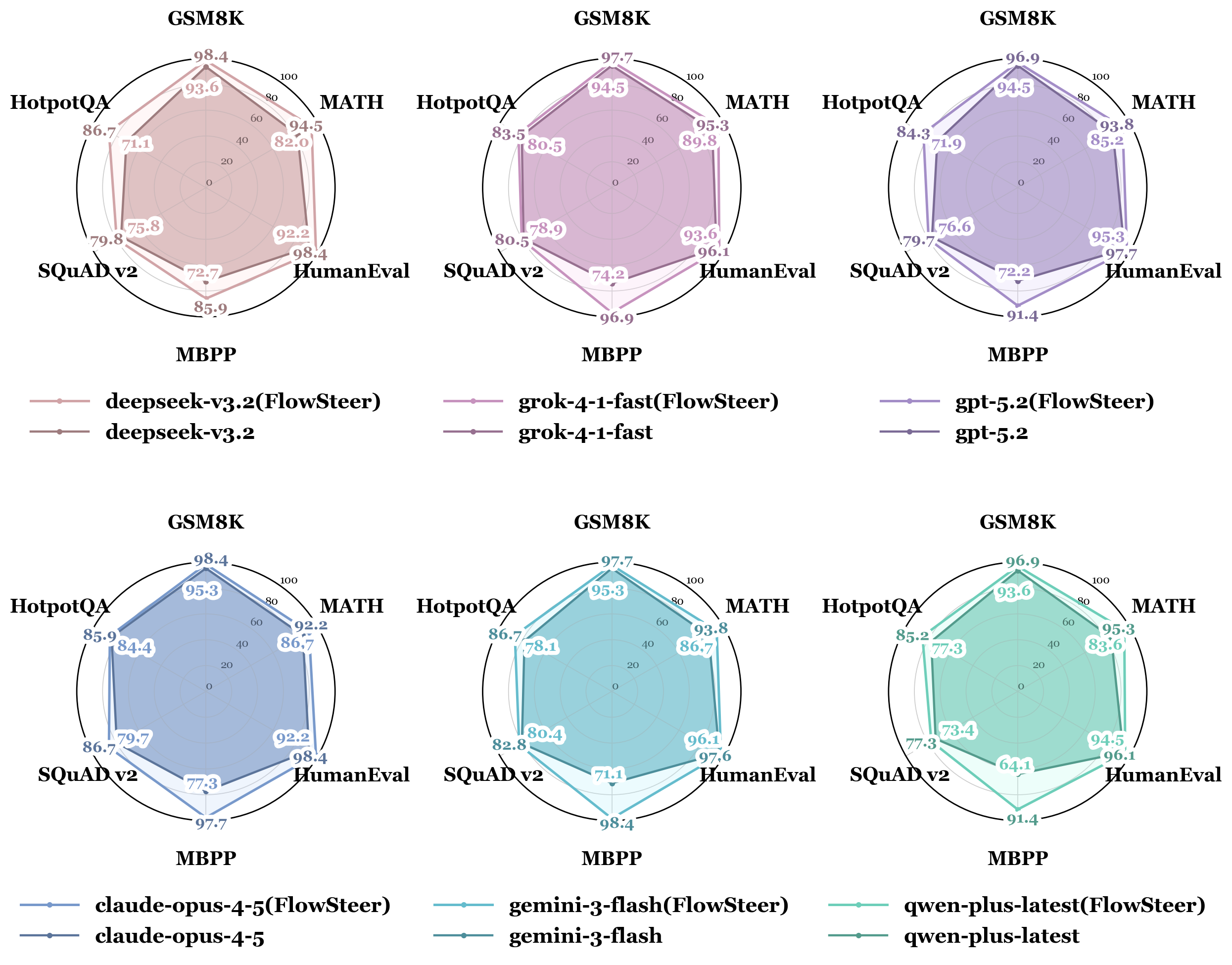
Consistent improvement across 6 LLM backends
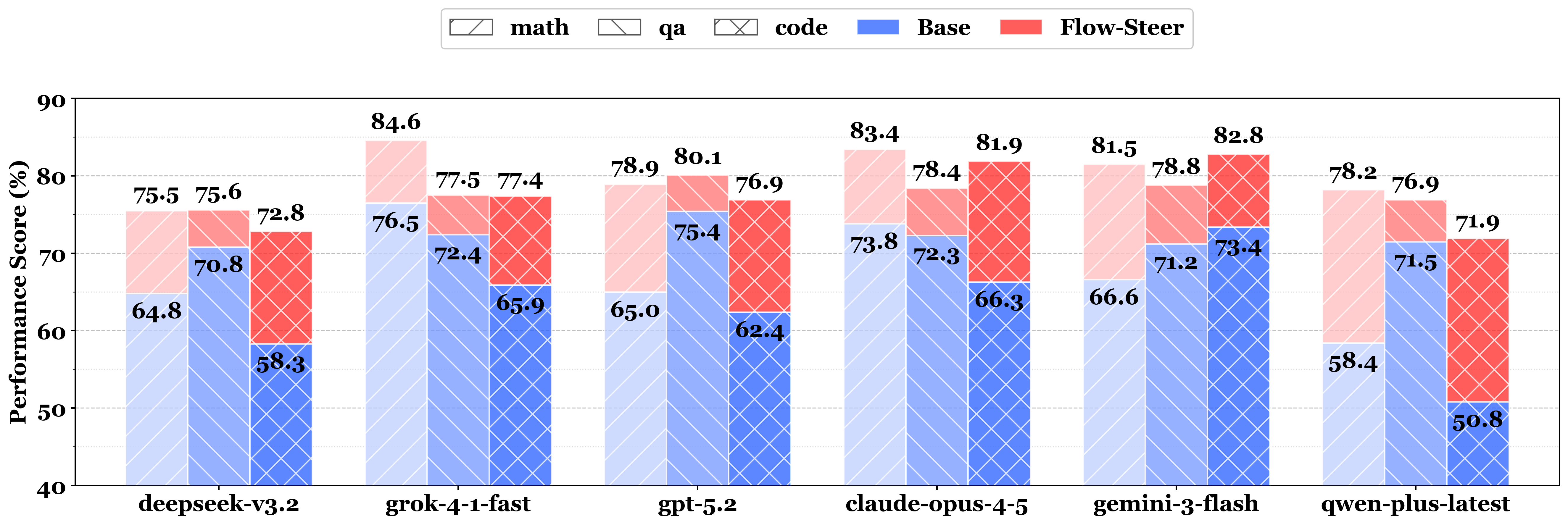
FlowSteer (red) vs Base (blue) on Math/QA/Code
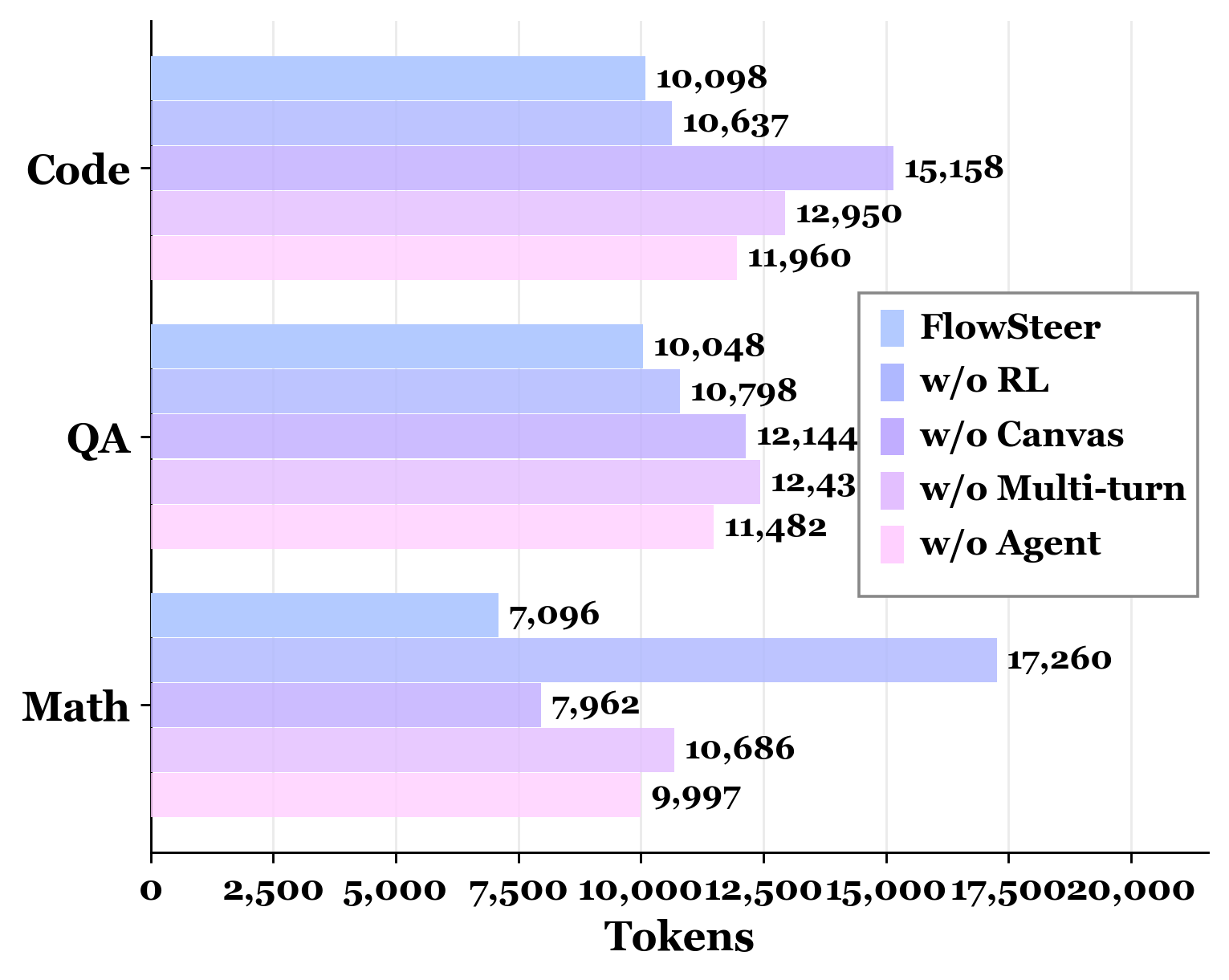
Up to 59% reduction
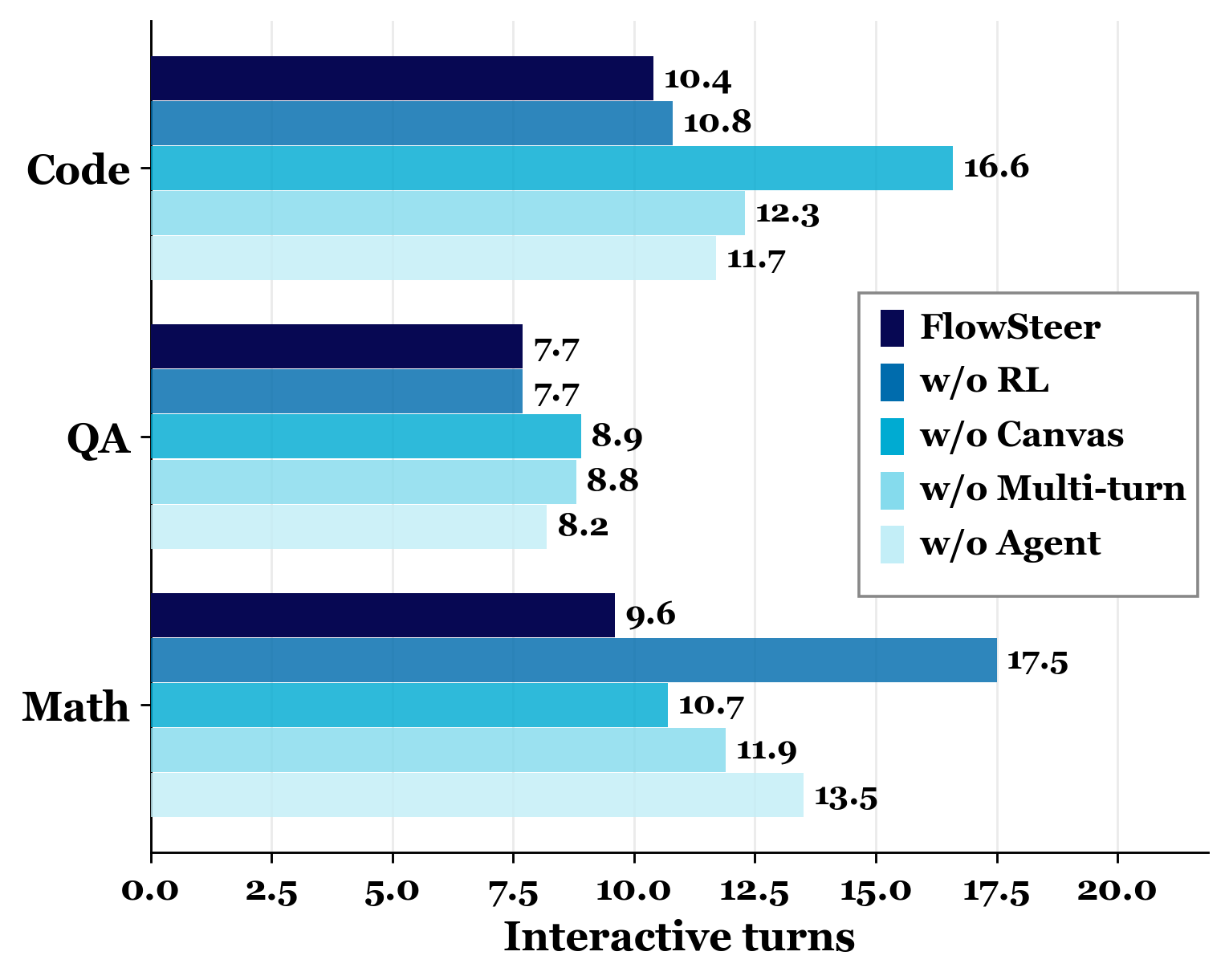
Fewer turns needed